Keywords
Multi agent system; Aspects; Ontologies; Labelling
Introduction
The base of our behavior coincides with computational principles, whose comprehension is the central objective of the cognitive science, artificial intelligence, and neuroscience [1]. Cognitive neuroscience explores the neural bases of cognition, including perception, attention, memory, problem solving, and decision making [2]. This paper contributes to the development of computational modelling base on mathematical psychology and cognitive neuroscience, what today is named as computational neuroscience [3-5]. In terms of Artificial Intelligence, the multi agent systems can offer a solution to the development of complex problems. Nevertheless, there´s a remarkable increase in the complexity of the system, therefore, the necessity to implement new technics increase too [6].
In the last years, we have seen the rapid growth in the use of applications for labelling, both in the number of applications of labelling associated with images, and in the number of users taking part in communities of labelling. This growth nowadays exceeds our comprehension of how there are done the annotations that turn out to be efficient and productive for a range of applications and of users.
The systems of labelling are often located in opposition to the taxonomic models, and two types of these systems are commonly cited:
1. The user's interfaces for annotation based on a closed and hierarchic vocabulary, are inflexible.
2. And, that a strict tree of concepts that does not reflect his use and intentions.
The first cite is valid, but it can be easily treated with dynamic ontologies and better mechanisms for User Interface (IU). Much of the second critic it is not so much an edition with the taxonomy (ontology) by itself, but something with the problematic models that reinforce the users into putting one hierarchy concepts. Much of this edition can be treated using aspects ontologies that separate the diverse aspects of labelling attempts. Some of the tags commonly used in media annotation include the localization, the associated activity, several aspects of the painting (art, people, flora, fauna, objects, in another) and especially in the context in which they are shared due to the emotional response that these tags involve [7-12]. The labels provide a simple and direct mechanism to create annotations that reflect a variety of aspects, and also provide direct means for the boarding of a search. The search, at least purely base on labels, tends to have a low memory functioning (this can be partially mitigated with an IU that conforms an aligned vocabulary). Furthermore, when a primary search shows a large number of results, the labels do not support intuitive or efficient models of the refinement of the question. In the best-case scenario, the users nowadays can refine the search that uses clusters of (statistic) related concepts. Although sometimes is useful, it is very difficult to evaluate.
Hierarchy models can describe the distinction between polythetic clusters and monothetic clusters in which all the members share one characteristic. Because of this, it has been discussed (and we agreed) that the users have a better understanding of the monothetic clusters [13]. Furthermore, due to this, the polythetic clusters are difficult to label compared with the monothetic clusters that are easy to label, being adapted to diverse common paradigms of the interface, such as directed navigation, limited hierarchies for the refinement of the question, among others. In some systems for personal information, search mechanisms base on aspects have been explored, as well as in hierarchies and therefore the system demonstrated the utility of the interface search of aspects for image browsing [13,14]. Although some members of the community of labelling reject the taxonomy, adding for example, del.icio.us (https://del.icio.us). We believe that the users should not have to decide between the models that are purely base on label and the purely taxonomic models with close vocabularies. We are currently exploring a model that is able to balance statistics natural language processing techniques, along with knowledge of the domain to induce the ontology that can be balance upon the final response. Our objective is a system that preserves the flexibility of an interface that marks with a label for the annotation, as long as it benefits of the power and utility of an aspect ontology in the browsing and visualization of the interface. We present early results of a model based in symbolic logic for the label system of Metroflog (https://www.metroflog.com), proving the potential for the technique to induce the convenience ontology for the browsing of the user´s interface. The rest of the article describes the approximation, the set of tests utilizing multi agent systems as well as the evaluation of the system, in addition to a proposal for a refined model and how this one would fit in the logistics of a labeling community in Metroflog.
Methods
Sanderson et. al. described a simple statistical model of symbolical logic, where X presupposes Y if [13]: P (x|y >= 0.8) and P (y|x < 1). This co-occurrence model is applied to the terms of the concept extracted of retrieved documents for a directed question (where a “query” search is a great help in adapting the domain of terms) [13].
Table 1 shows the results obtained using the same technique was adapted to contribute in the photographs of a historical collection [13]. In this Table 1, we can see that the resulting taxonomies are quite noisy because many of the proposed pairs of presupposition are incorrect, especially because the vocabularies of the domain are focused by the original questions. Despite this, this kind of models generate the taxonomy that reflects the real use, and in this way, they adequately satisfy the applications for labeling. Many other investigations have experimented with inducing ontology using statistical Neuro-Linguistic Programing (PLN) techniques [14-17]. Some of them depend on at least of the grammatical discourse, and because of this, it can be applied only in natural language contexts [15,17,18].
| Author |
BDI |
Multi agent |
Ontologies |
Labeling |
Model of emotion |
Art and Aesthetics |
Year |
Title |
| Parrott W |
X |
X |
X |
X |
√ |
X |
2001 |
Emotions in social psychology. |
| Edmund T |
X |
X |
X |
X |
√ |
√ |
2017 |
Neurobiological foundations of aesthetics and art. |
| Pentti M |
X |
X |
X |
X |
√ |
√ |
2017 |
Emotions, values, and aesthetic perception. |
| Righ S |
X |
X |
X |
X |
X |
√ |
2017 |
Aesthetic shapes our perception of every-day objects: An ERP study. |
| Alex MG |
X |
X |
X |
√ |
√ |
X |
2018 |
Applying multi-label techniques in emotion identification of short texts. |
| Fernández M |
X |
X |
X |
√ |
X |
X |
2018 |
Labelled port graph – A formal structure for models and computations. |
| Yee KP |
X |
X |
X |
√ |
X |
X |
2003 |
Faceted metadata for image search and browsing. |
| Sanderson A et al. |
X |
X |
√ |
√ |
X |
X |
1999 |
Deriving concept hierarchies from text. |
| Naaman M |
X |
√ |
√ |
√ |
X |
X |
2004 |
Context data in geo-referenced digital photo collections. |
| Mani I et al. |
X |
√ |
√ |
√ |
X |
X |
2004 |
Automatically inducing ontologies from corpora. |
| Vicente JJ |
X |
√ |
√ |
√ |
X |
X |
2003 |
Estudio de métodos de desarrollo de sistemas multiagente. |
| Tinio PP |
X |
X |
X |
X |
√ |
√ |
2018 |
Characterizing the emotional response to art beyond pleasure: Correspondence between the emotional characteristics of artworks and viewers´ emotional responses. |
| Cela-Conde CJ |
X |
X |
X |
X |
√ |
√ |
2018 |
Art and brain coevolution |
| Siri F |
X |
X |
X |
X |
X |
√ |
2018 |
Behavioral and autonomic responses to real and digital reproductions of works of art. |
| Christensen JF |
X |
X |
X |
X |
X |
√ |
2018 |
Introduction: Art and the brain: From pleasure to well-being. |
| Che J |
X |
X |
X |
X |
X |
√ |
2018 |
Cross-cultural empirical aesthetics. |
| Zaidel DW |
X |
X |
X |
X |
X |
√ |
2018 |
Culture and art: Importance of art practice, not aesthetics, to early human culture. |
| Clough P |
X |
X |
X |
X |
X |
|
2005 |
Automatically organizing images using concept hierarchies. |
| Cambria E |
X |
X |
X |
X |
√ |
X |
2012 |
The hourglass of emotions. |
| Scherer K |
X |
X |
X |
X |
√ |
X |
2000 |
Psychological models of emotion. |
| Georgeff M |
√ |
√ |
X |
X |
X |
X |
1997 |
The belief-desire-intention model of agency. |
| Baitiche H |
√ |
√ |
X |
X |
X |
X |
2017 |
Towards A generic predictive-based plan selection approach for BDI agents. |
| Yu W |
√ |
√ |
X |
X |
X |
X |
2012 |
An extension dynamic model based on BDI agent. |
| Phung T |
√ |
√ |
X |
X |
X |
X |
2005 |
Learning within the BDI framework: An empirical analysis. |
| Dumais S et al. |
X |
X |
√ |
√ |
X |
X |
2003 |
Stuff I’ve seen: A system for personal information retrieval and re-use. |
| Hearst M |
X |
X |
√ |
√ |
X |
X |
1992 |
Automatic acquisition of hyponyms from large text corpora. |
| Henríquez C |
X |
X |
√ |
√ |
X |
X |
2016 |
Ontologies for aspects automatic detection in sentiment analysis. |
| Hearst M |
X |
X |
√ |
√ |
X |
X |
1999 |
User interfaces and visualization. |
| Guerra-Hernandez A |
√ |
√ |
X |
X |
X |
X |
|
Learning in BDI multi-agent systems. |
| Cisneros M et al. |
√ |
√ |
√ |
√ |
√ |
√ |
2018 |
This research. |
Table 1: Comparative studies [13].
In addition, there had been attempts to match concepts to existing ontologies such as Word Net; these models can be intrinsically less noisy, but since Word Net is based on standard English vocabulary, this can make the adaptation of stories difficult in dynamic and idiosyncratic vocabulary that emerges in labeling application.
Exploratory approach
Assumption step: We adapted the model´s set based in the model of Sanderson et. al. [19] to the Metroflog labeling system, adjusting the statistical studies to reflect the ad hoc use, adding filters to the control for the highly idiosyncratic vocabulary. So, X potentially includes a yes if:
P (x|y ≥ t) and P (y|x < t),
Dx ≥ Dmin, Dy ≥ Dmin,
Ux ≥ Umin, Uy ≥ Umin
Where: t is the trend of co-occurrence, Dx is the # of documents in the results where the term x occurs, and it may be greater than a minimum value Dmin and, Ux is the # of users using x in at least one annotation of image and it can be larger than a minimum value Umin.
We filter the input documents (i.e., the photos), requiring a minimum of 2 terms for the label, so that the co-occurrence was defined. We conducted a series of experiments, varying the parameters t, Dmin, and Umin. We searched for a balance that minimize the error rate and maximize the number of proposed pairs of assumptions. Considering that using stricter values for the co-occurrence threshold (around 0.9) reduces the error rate, but dramatically reduces the number of proposed pairs. For this case, the useful values were used between 0.7 and 0.8, and the values under the comparable value, were determinate empirically [19]. Then, the model was more sensitive to changes in Umin than Dmin. From there that Fix Umin to anything below 5, delivered many of the highly idiosyncratic terms in noisy assumption pairs, where a useful range was from 5 to 20 obtaining varied values of Dmin from 5 to 40. Demonstrating with this, that our model is quite useful to adjust the value.
It should also be mentioned that both values were increasing slowly while the number of documents increased. And with a fixed entry below 1 million photos, the vocabulary was less stable and so the model was more sensitive to the parameters.
Pruning and tree reinforcement: Once the co-occurrence statistics are calculated, the pairs of candidate terms are selected using the specified constraints. Then we build a graph of possible parent-child relationships, and we filter out the co-occurrence of the nodes with the ancestors that are logically about their father. Once the co-occurrence statistic is calculated, the term pairs of the candidate are selected using the specified restrictions. Then we build a graph of possible father-son relationships, and we filter out the co-occurrence of nodes with ancestors that are logically about their father. That is because a given relationship of the term must be reinforced, therefore we increase the weights of each. Finally, we consider each leaf in the tree and choose the best trajectory to a root, considering the (reinforced) weights of the co-occurrence for the potential parents of each node, and we join the trajectories in trees.
With document systems large enough, many of the trees are quite large, for example, cities with points of interest. We observed a disproportionate number of erroneous trajectories in single-instance (singleton) and double-instance substructures (doubleton), with respect to the larger substructures, then we filter these out jointly. This is justified because the total number of trees of the candidate was very large for these runs (from 500 to more than 3000 candidate pairs are met by a basic assumption and filtering criteria), and the final goal is to provide enough structure to assist in making sense and navigational guidance through the collection. A secondary goal was to improve the search by deducting the terms of the father for the images with son terms, and in this sense some recoveries are certainly sacrificed in filtering out the singleton and doubleton trees. We believe that users of the assumption trees will be more sensitive to accuracy than to recovery, this aspect of the model must be evaluated with large-scale user studies.
Data set and analysis
We used a snapshot of the Meta base data of Metroflog from April of 2007 (Figure 1). To this date, there were a total of seven million photos, and around 37 million of entries in total. Approximately, 5 million of these photos were marked as “not public”, so we excluded them from the experimental system. The tables were modified making the data of the user anonymous (I.D.s including photo) and all the images with less than 2 terms were filtered. This resulted in a set of tests of about 7000 images. The associated vocabulary was limited to 200K and 5000 pairs were generated in total (an exact number is not available, because we filtered some numbers while utilizing the Multiagent system). Utilizing the multiagent system, we determined the cultural aspects of the evaluated community. Between Metroflog´s notes, the vocabulary turns out to be opposite with regard to spelling and terms limits (for example, "Los Ángeles" demonstrates often how the two terms “los” and “angeles” can be analyze due to a non-intuitive interface of the label´s entry). Furthermore, there are many idiosyncrasy terms in the notes. These terms varied from the described personal events as a labelling phrase ("johnandmaryswedding" – indicating a possible confusion).
Figure 1: Influence of personal variables on the rate of occurrence of disease like SCH and OCD.
Supposition evaluation
The resulting trees will be evaluated manually. Each supposition pair proposed will be marked as correct, reversed, related, and as synonymous (including ontology variants in common terms such as flower"/"Blume"/"fleur"/"bloem" etc., or noise (entirely erroneous)). The second figure demonstrates several examples of the generated trees. A lot of the concepts, such as "Los Ángeles", are points of interest; several are possibly related and there is an example of entropy that is the result of a statistics model. In the second example each one of the nods is a “crystal” hyponym; although maybe for an art historian, this could be conceiving as an “acceptable” model of domain in the representative use inside Metroflog´s community. Based on our own experience and the experience of others [18], we presume that the images will be noted and retrieved as easily as possible on having accentuated several aspects of the key word: location, activity and images. Metroflog´s community seems to be accentuating other aspect as well, that could describe as the emotion or response. Our results show that a large proportion of the shared vocabulary is linked to the location names, although we count with the refinements of the model to produce more balance with other aspects. For the localization, we were considering a combination of names for geographic places, as well as the points of interest that demark the place with more activity. This way we consider "Los Ángeles" as reasonable father of "Chinese Theater". In the sense of a pure type of relation, this could not be sustaining, however, it is entirely reasonable for the utility of locating an image. In the same context, "Los Ángeles" can be related but is not a father of "muni" neither of "streetfair". For generic terms like "lago" and "parque", we were considering instances for lakes or parks that could be reasonably sons. In the most usual images of the relationship type, we utilize "dog", but we included specific breeds such as in “food” we included "kimchee" and "creamcheese" were “restaurant” is related only. The personal relationships are less useful for a question in a large photo that shares the landscape just like in Metroflog, so we looked at almost all the personal names as noise in any pair context.
Table 1 compares the results of the related supposition models with our results. In some investigations, a high number of aspects is reported, and the limiting questions in the vocabulary are attributed to this. This investigation also presents an application much like ours and that´s how we provided a useful bottom line [19]. We believe that their model can be better applied if it was focused in the whole vocabulary instead of a focused question. The statistics model appears to contain an inconsistency (the second term should be expressed as P (y|x < 0.8) and not P (y|x < 1)), although this can be a typographic error in the articles [13,19,20].
Proposed model
The early results are promising enough, so we feel encourage to realize additional work. Our model produces the substructures that show different aspects, generally speaking, but it cannot categorize concepts in aspects. We´ve arranged a series of changes to the model to address this, as is proposed in our model in Figure 2.
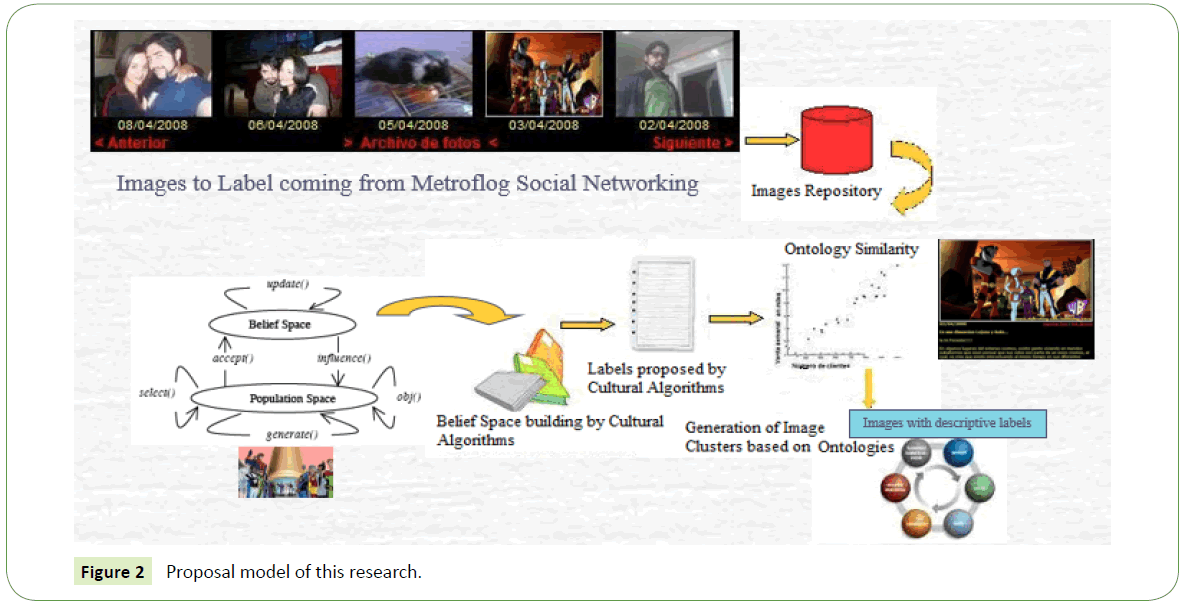
Figure 2: Proposal model of this research.
Migration to a purer probabilistic model
We are currently working to be able to express the assumption, the construction of tree pruning, and the classification of the aspect, all together in a unified probabilistic model, something like the model proposed by Mani et. al. from Corpora [17]. For this, we are proposing a more robust probabilistic model and we are incorporating concepts such as "the number of authors using a label" at a characteristic level and not as a simple threshold, as is currently the case.
Add the help for repeated or badly written data
We would also like to add better help in cases of repetitions and misspellings. We believe that the interface currently used by Metroflog produces more of these than the models that support the suggestion of the label (example, del.icio.us). This is possible by representing the resulting ontology as a graph of the concepts that have several labels, variable graphs can be associated probabilistically. And the most common spelling is the natural label.
Exploring morphological tools
We are also exploring morphological analysis, concentrating on the potential to combine aspects. This because the initial analysis of the data indicates that certain morphological techniques (for example, eliminating the plural and the stem from the verb-gerund) may be appropriate for some aspects, but not for others.
Seeds with ontological aspects of ontology
A significant problem with the assumption is its common use, since people tend to name generic concepts (neither in a very general, nor too specific) way. In particular, people use few generic and unspecific concepts such as "country" or "continent" for location, and "mammal" or "plant" for an image. In our results, for example, certain country names, although specified, were rarely mentioned along with those of cities. However, these higher ontological concepts are freely available in the form of dictionaries and common taxonomies. Therefore, we plan to specify our new model with these superior model ontologies in a specific domain (DUMO's). In this way we reduce the weakness inherent in the assumption, serving another purpose as well. On the other hand, by specifying the higher-level structure of ontology, the aspect model that makes sense for most users can be fulfilled. And since it is an entry in the model, we can easily test variants on it with the same user base.
Moderation of the support community
While we expect the refined model to reduce noise (errors) in our results, we believe that the model can be improved by deploying it not as a fully automated process, but as a productivity tool. Many labeling applications have a model set for the community, including moderator enthusiasts for popular secondary domains. If the statistical model can suggest ontology, the set of advisors will only need to approve or reject the proposed relationships. Once a baseline is established, it will require little effort from the advisors to keep the ontology updated and fresh, reflecting current usage. In addition, the statistical model reflects the use of the community, with the moderators acting as supervisors.
Results
In order to properly determine the functionality of our intelligent application, we detail each of our examples in our design of experiments.
1. First step related with our Graphic User Interface (GUI) and associated with our BDI Model (Figure 3). The main screen consists on the buttons. The first button “Train” initiates the BDI system. When activated, the system starts building a graph with the labeled images contained on an initial data base. The graph will be used to label new pictures. The second and third button open the upload screen and the catalog screen, respectively.
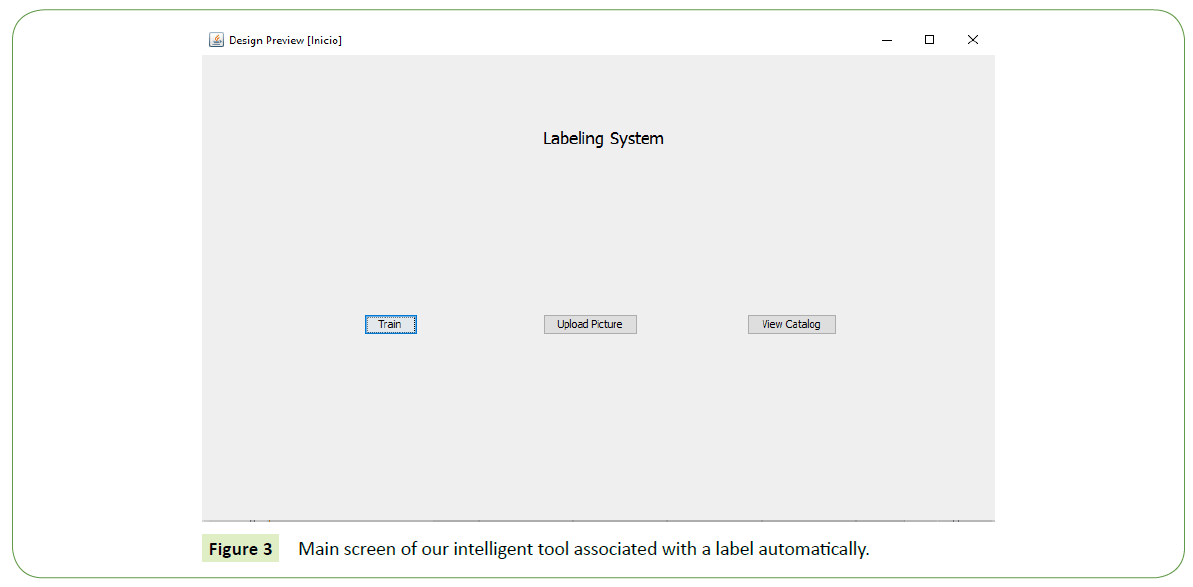
Figure 3: Main screen of our intelligent tool associated with a label automatically.
2. Upload picture: Here the user can upload pictures to be label by the BDI system. These pictures are upload from the user computer. The user may include some labels. On the example, the user has selected a picture and some labels, as is shown in Figure 4.
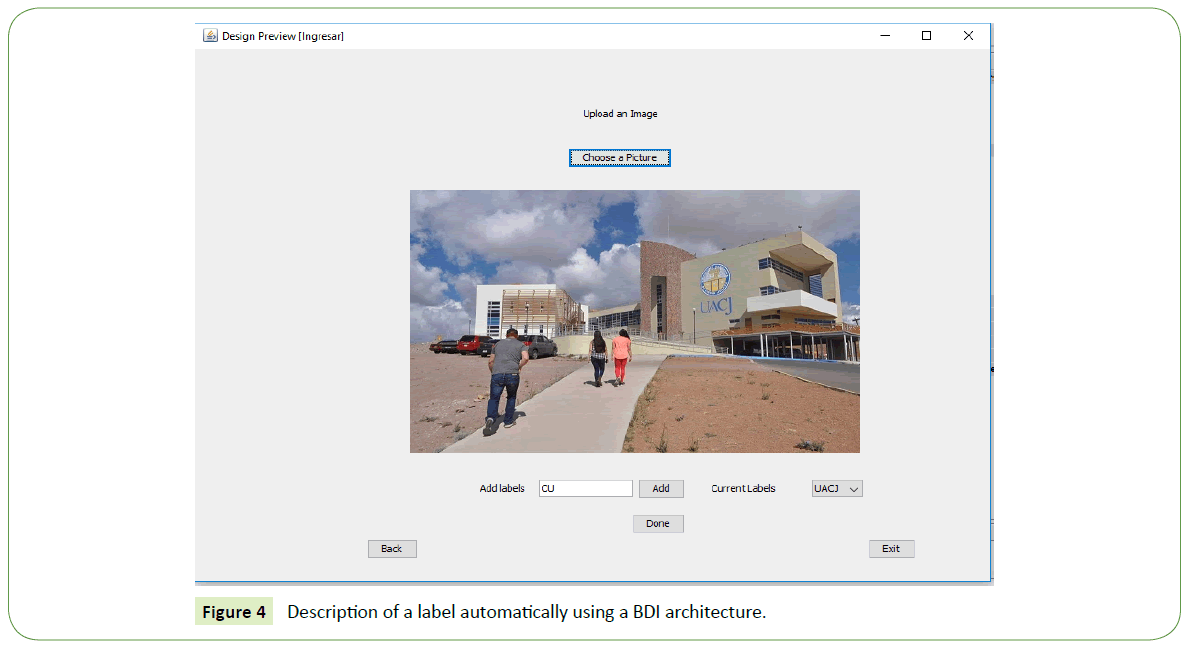
Figure 4: Description of a label automatically using a BDI architecture.
3. View catalog: This screen shows the pictures contained on the data base. The screen also shows the labels associated with each picture. A picture with some labels is shown on the following example, as is shown in Figure 5.
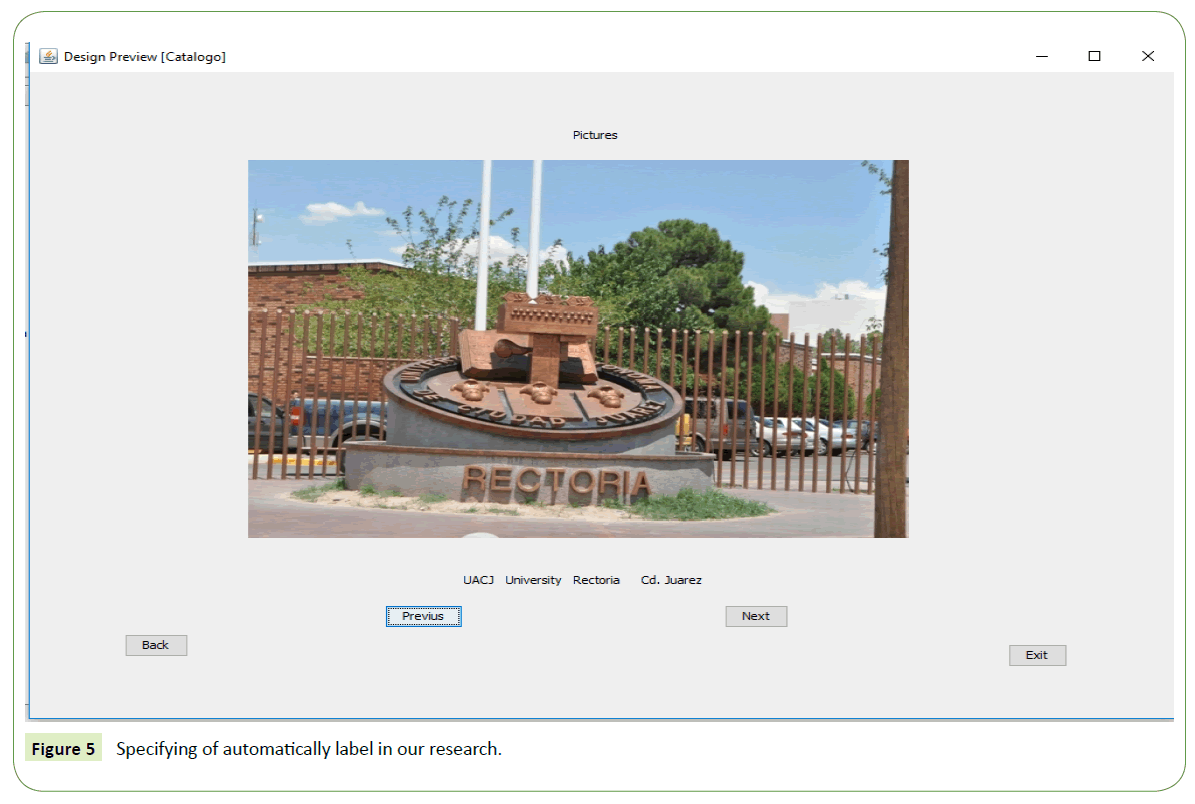
Figure 5: Specifying of automatically label in our research.
Our results show that a large proportion of the shared vocabulary in the sample is linked to the location names within the emotional response of the community, although we will refine the model further to produce more balance with other aspects in regard to the model of emotion. The images were noted and retrieved very easily accentuating several aspects with key words, such as location, activity and images, that showed to us the emotion exposed in the labelling.
Every single one of the resulting trees were evaluated manually. In addition to this, each supposition pair proposed was mark as correct, reversed, related, and as synonymous, giving us a hint to induce ontology aspects in further research. A better explain comparative is analyzed in Figures 5-7.
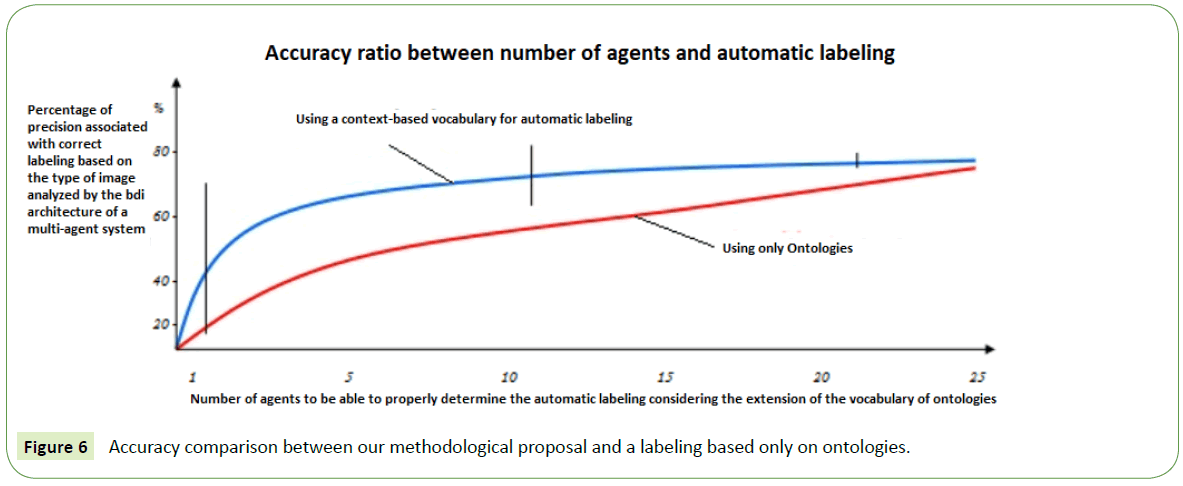
Figure 6: Accuracy comparison between our methodological proposal and a labeling based only on ontologies.
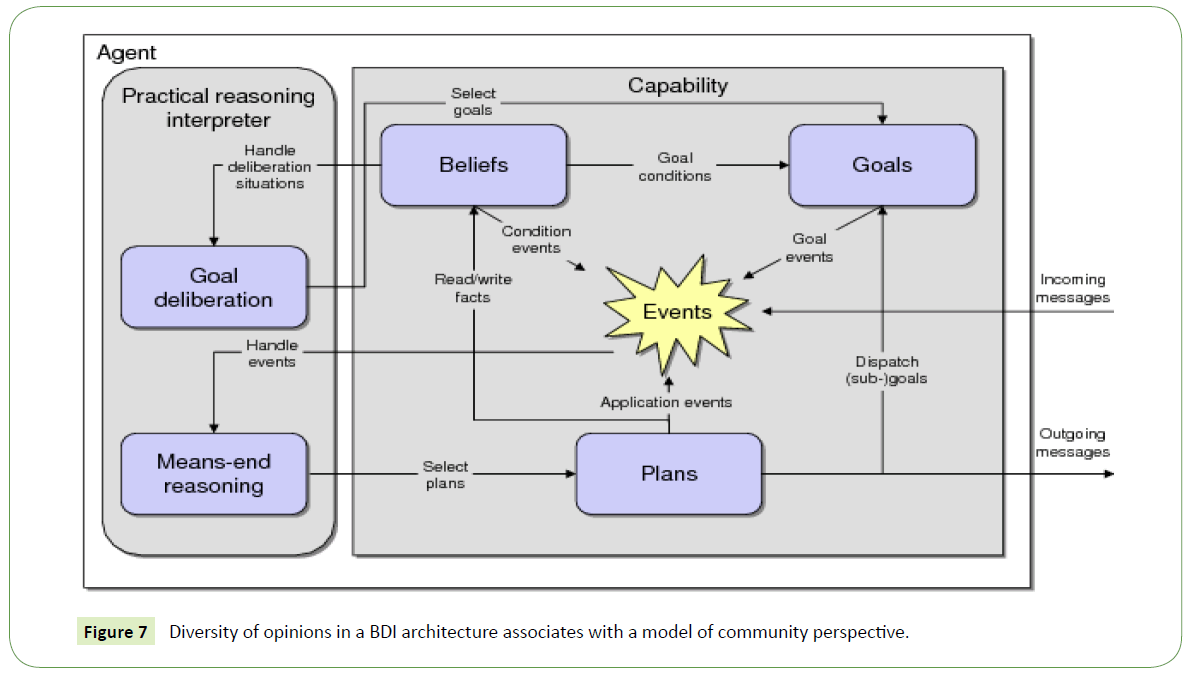
Figure 7: Diversity of opinions in a BDI architecture associates with a model of community perspective.
Discussion
The limitation of our study is the interface currently use by Metroflog, because it produces more repetitions and misspellings than the models that support the suggestion of the label. Another limitation is that our model produces the substructures that show different aspects, but it still cannot categorize concepts in different ontology aspects.
Finally, we are currently conducting research to specify our new model with superior model ontologies like DUMO's and other dictionaries, that can be developed within the model of emotion that we use to analyze the emotional response in the tags.
Conclusions and Future Research
We´ve described a model based on suppositions to induce labeling ontologies that produces promising early results. We hope to improve the accuracy of the model, as well as to induce ontology aspects with the emotional response within the labels. The results will support interfaces that will lead to a more efficient searches, and existing community models can be reasonably integrated by moderators.
A BDI architecture associated with a Multiagent System, and with an incremental vocabulary of ontologies could describe in a better way images associated with scenarios with a high incidence of determinant factors related to paradigmatic changes in the perspective of a social group, as it can be observed.
Acknowledgments
A K. Valádez partner of Metroflog, for the access to the meta base data of Metroflog.
24696
References
- Naselaris T, Bassett DS, Fletcher AK, Kording K, Kriegeskorte N, et al. (2018) Cognitive computational neuroscience: A new conference for an emerging discipline. Trends Cogn Sci 22: 365-367.
- McClelland JL, Ralph MA (2015) Cognitive neuroscience. International Encyclopedia of the Social & Behavioral Sciences 4: 95-102.
- Palmeri TJ, Love BC, Turnerc BM (2017) Model-based cognitive neuroscience. J Math Psychol 76: 59-64.
- Sejnowski TJ (2015) Computational neuroscience. International Encyclopedia of the Social & Behavioral Sciences 4: 480-484.
- Eliasmith C (2007) Computational neuroscience. Philosophy of Psychology and Cognitive Science pp: 313-338.
- Vicente JJ, Botti VJ (2003) Estudio de métodos de desarrollo de sistemas multiagente. Inteligencia Artificial. Revista Iberoamericana de Inteligencia Artificial 7: 65-80.
- Tinio PP, Gartus A (2018) Characterizing the emotional response to art beyond pleasure: Correspondence between the emotional characteristics of artworks and viewers´ emotional responses. Progress in Brain Research 237: 319-342.
- Cela-Conde CJ, Ayala FJ (2018) Art and brain coevolution. Progress in Brain Research 237: 41-60.
- Siri F, Ferroni F, Ardizzi M, Kolesnikova A, Beccaria M, et al. (2018) Behavioral and autonomic responses to real and digital reproductions of works of art. Prog Brain Res 237: 201-221.
- Christensen JF, Gomila A (2018) Introduction: Art and the brain: From pleasure to well-being. Prog Brain Res 237: xxvii-xlvi.
- Che J, Sun X, Gallardo V, Nadal M (2018) Cross-cultural empirical aesthetics. Prog Brain Res 237: 77-103.
- Zaidel DW (2018) Culture and art: Importance of art practice, not aesthetics, to early human culture. Prog Brain Res 237: 25-40.
- Clough P, Joho H, Sanderson M (2005) Automatically organizing images using concept hierarchies. Proceedings of Multimedia Information Retrieval.
- Dumais S, Cutrell E, Cadiz JJ, Jancke G, Sarin R, et al. (2003) Stuff I’ve seen: A system for personal information retrieval and re-use. In SIGIR 2: 1.
- Hearst M (1992) Automatic acquisition of hyponyms from large text corpora, in “Proc. of COLING 92”, Nantes.
- Hearst M (1999) User interfaces and visualization. Modern Information Retrieval. ACM Press, USA.
- Mani I, Samuel K, Concepcion K, Vogel D (2004) Automatically inducing ontologies from corpora. Proceedings of CompuTerm 2004: 3rd International Workshop on Computational Terminology, COLING'2004, Geneva.
- Naaman M, Harada S, Wang Q, Garcia-Molina H, Paepcke A (2004) Context data in geo-referenced digital photo collections". In proceedings, Twelfth ACM International Conference on Multimedia (ACM MM 2004).
- Sanderson M, Croft B (1999) Deriving concept hierarchies from text. In: Proceedings of the 22nd ACM Conference of the Special Interest Group in Information Retrieval.
- Yee KP, Swearingen K, Li K, Hearst M (2003) Faceted metadata for image search and browsing. In: Proceedings of the SIGCHI conference on Human factors in computing systems.